
ComplexHeatmap是Zuguang Gu博士开发的一款可以绘制复杂热图的一个包,即可实现简单热图的功能,更能绘制更复杂的热图。复杂的热图有效地可视化不同数据集源之间的关联并揭示潜在模式。ComplexHeatmap包提供了一种高度灵活的方式来排列多个热图并支持各种注释图形。
ComplexHeatmap简介篇
本文所有内容引用:Zuguang Gu, Roland Eils and Matthias Schlesner, Complex heatmaps reveal patterns and correlations in multidimensional genomic data, Bioinformatics, 2016
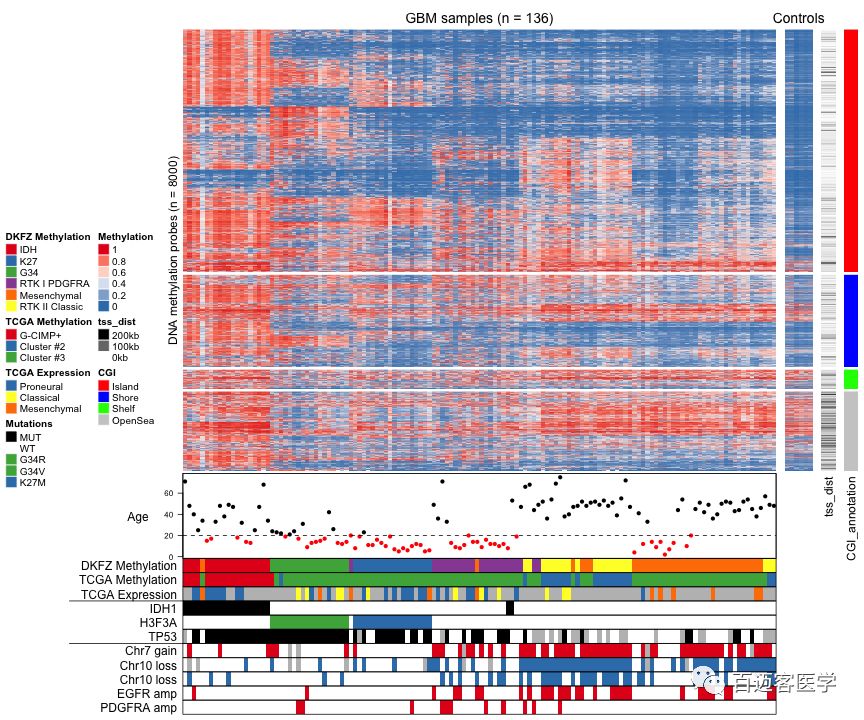
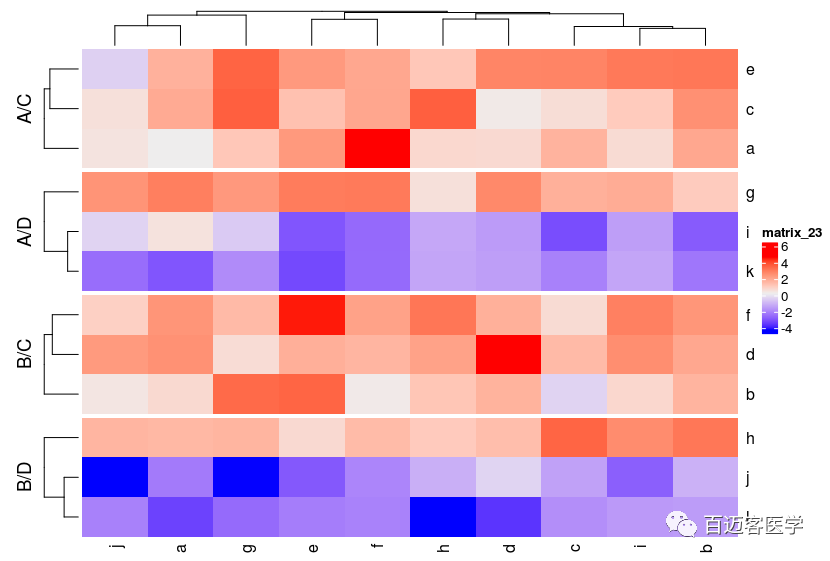
图1 甲基化图谱的绘制
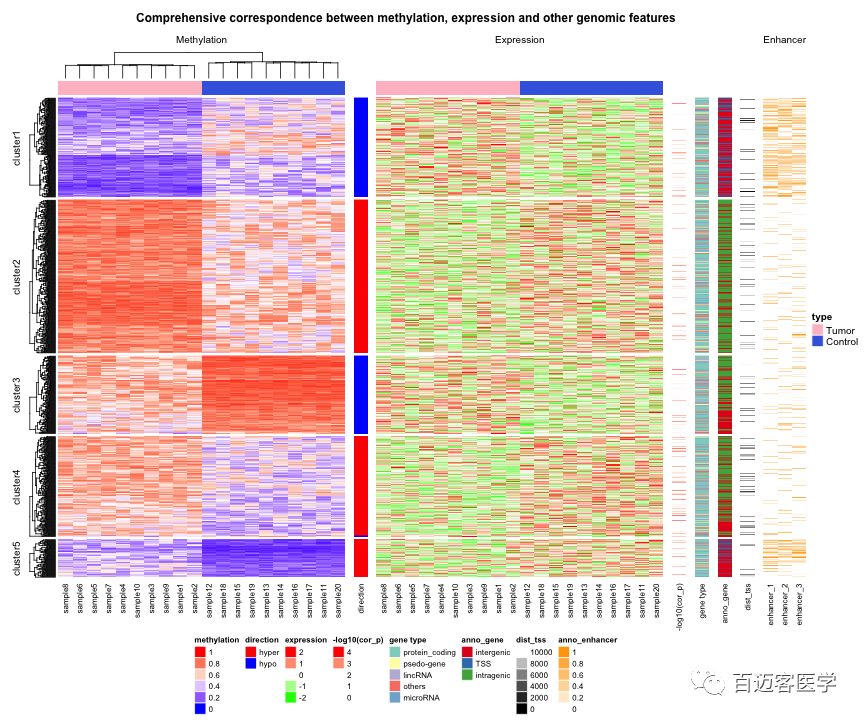
图2 甲基化、表达谱及其他基因组属性相关性绘图
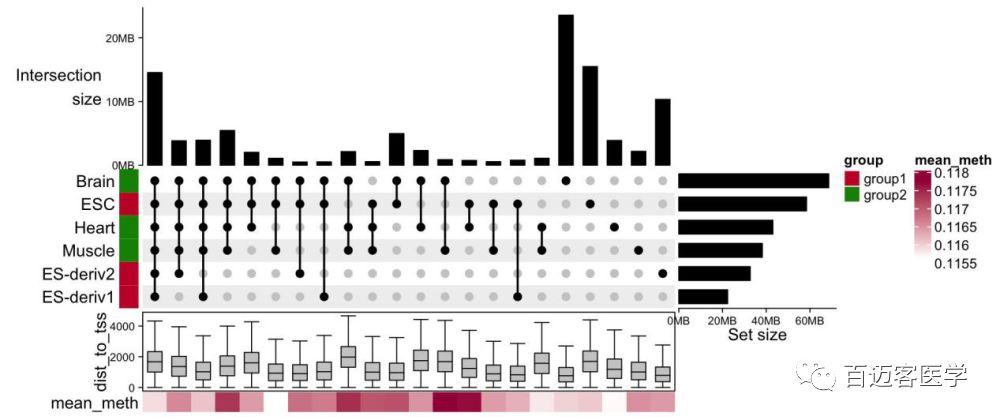
图3 Upset plot
ComplexHeatmap安装篇
1)可从 Bioconductor获得:
install.packages(“BiocManager”)
BiocManager::install(“ComplexHeatmap”)
2)从Bioconductor下载ComplexHeatmap_1.18.1.tar.gz,然后:
3)新版本可从GitHub上获得:
install_github(“jokergoo/ComplexHeatmap”)
总而言之,请费尽心机把这个包安装到你的R中
参数详情篇
#matrix:数字或字符型矩阵(可以是离散或连续型数值)
#col:定义热图颜色,对离散型数据,col可以是一个向量;对连续型数据,col可以是一个函数,也可以用colorRamp2 函数生成
#name:热图图例名称
na_col = “grey”,
#ComplexHeatmap允许数据中含有NA,需要通过参数na_col来控制NA的颜色
color_space = “LAB”,
#当矩阵是数值型矩阵,col是一个向量时,控制内插颜色
rect_gp = gpar(col = NA),
#rect_gp:热图体区矩形的参数,如设置举行边框为白色
cell_fun = NULL,
#cell_fun:自定义在cell中增加绘图项的函数。7个参数:i(row index,矩阵中的行index), j(column index,矩阵中的列index), x,y(热图体区中中间点的坐标),width,height(cell的宽度和高度),fill(cell的填充颜色)
row_title = character(0),
#row_title:行标题
row_title_side = c(“left”, “right”),
#row_title_side:行标题位置,左(“left”),右(“right”)
row_title_gp = gpar(fontsize = 14),
#row_title_gp:设置行标题的文本属性,此处为字体大小为14
row_title_rot = switch(row_title_side[1], “left” = 90, “right” = 270),
#row_title_rot:行标题的旋转角度,可选为0,90,270
column_title = character(0),
#column_title:列标题
column_title_side = c(“top”, “bottom”),
#column_title_side:列标题位置,上(“top”),下(“bottom”)
column_title_gp = gpar(fontsize = 14),
#column_title_gp:设置列标题的文本属性
column_title_rot = 0,
#column_title_rot:列标题的旋转角度,可选为0,90,270
cluster_rows = TRUE,
#cluster_rows:是否行聚类
clustering_distance_rows = “euclidean”,
#clustering_distance_rows:行聚类的距离方法,默认为“euclidean”,也可以为自定义函数
clustering_method_rows = “complete”,、
#clustering_method_rows:行聚类的方法,默认为“complete”,可参考hclust
row_dend_side = c(“left”, “right”),
#row_dend_side:行聚类树位置,左(“left”),右(“right”)
row_dend_width = unit(10, “mm”),
#row_dend_width:行聚类树的宽度,unit对象
show_row_dend = TRUE,
#show_row_dend:是否展示行聚类树
row_dend_reorder = TRUE,
#row_dend_reorder:对行重新排序,该值可以是逻辑值或包含用于重新排序行的权重的向量
row_dend_gp = gpar(),
#row_dend_gp:绘图线的图形参数。如果已经提供了带有边渲染的树形图对象,则该参数将被忽略。
row_hclust_side = row_dend_side,
#row_hclust_side:已弃用
row_hclust_width = row_dend_width,
#row_hclust_width:已弃用
show_row_hclust = show_row_dend,
#show_row_hclust:已弃用
row_hclust_reorder = row_dend_reorder,
#row_hclust_reorder:已弃用
row_hclust_gp = row_dend_gp,
#row_hclust_gp:已弃用
cluster_columns = TRUE,
#cluster_columns:是否列聚类
clustering_distance_columns = “euclidean”,
#clustering_distance_columns:列聚类的距离方法,也可以为自定义函数
clustering_method_columns = “complete”,
#clustering_method_columns:列聚类方法,可参考hclust
column_dend_side = c(“top”, “bottom”),
#column_dend_side:列聚类树位置,上(“top”),下(“bottom”)
column_dend_height = unit(10, “mm”),
#column_dend_height:行聚类树的高度,unit对象
show_column_dend = TRUE,
#show_column_dend:是否展示列聚类树
column_dend_gp = gpar(),
#column_dend_gp:绘图线的图形参数。如果已经提供了带有边渲染的树形图对象,则该参数将被忽略。
column_dend_reorder = TRUE,
#column_dend_reorder:对列重新排序,该值可以是逻辑值或包含用于重新排序列的权重的向量
column_hclust_side = column_dend_side,
#column_hclust_side:已弃用
column_hclust_height = column_dend_height,
#column_hclust_height:已弃用
show_column_hclust = show_column_dend,
#show_column_hclust:已弃用
column_hclust_gp = column_dend_gp,
#column_hclust_gp:已弃用
column_hclust_reorder = column_dend_reorder,
#column_hclust_reorder:已弃用
row_order = NULL,
#row_order:行的顺序。如果选择此热图作为主热图,则可以轻松调整热图列表的行顺序。手动设置行顺序应关闭群集
column_order = NULL,
#column_order:列的顺序。它可以轻松调整矩阵和列注释的列顺序
row_names_side = c(“right”, “left”),
#row_names_side:行名称位置。
show_row_names = TRUE,
#show_row_names:是否展示行名称
row_names_max_width = default_row_names_max_width(),
#row_names_max_width:行名称的最大宽度。因为某些时候行名称可能很长,所以显示它们都是不合理的。
row_names_gp = gpar(fontsize = 12),
#row_names_gp:行名称文本属性
column_names_side = c(“bottom”, “top”),
#column_names_side:列名称位置
show_column_names = TRUE,
#show_column_names:是否展示列名称
column_names_max_height = default_column_names_max_height(),
#column_names_max_height:行名称的最大宽度。
column_names_gp = gpar(fontsize = 12),
#column_names_gp:列名称文本属性
top_annotation = new(“HeatmapAnnotation”),
#top_annotation:用HeatmapAnnotation函数构建的注释对象,在顶部添加注释信息
top_annotation_height = top_annotation@size,
#top_annotation_height:顶部注释信息展示的总高度
bottom_annotation = new(“HeatmapAnnotation”),
#bottom_annotation:用HeatmapAnnotation函数构建的底部注释对象
bottom_annotation_height = bottom_annotation@size,
#bottom_annotation_height:底部注释信息展示的总高度
km = 1,
#km:对行做k-means聚类的类数,若k>1,热图会根据k-means聚类对行进行分裂,对每个cluster,进行层次聚类
km_title = “cluster%i”,
#km_title:设置km时每个cluster的行标题。它必须是格式为“。*%i。*”的文本,其中“%i”由cluster的索引替换
split = NULL,
#split:行按照split定义的向量或者数据框进行分裂。但是,如果cluster_rows是聚类对象,则split可以是单个数字,表示将根据树上的拆分来拆分行
gap = unit(1, “mm”),
#gap:如果热图按行分割,则行切片之间的间隙应为单位对象。如果是矢量,则热图中的顺序对应于从上到下
combined_name_fun = function(x) paste(x, collapse = “/”),
#combined_name_fun:如果热图按行分割,如何为每个切片创建组合行标题? 此函数的输入参数是一个向量,它包含split中每列下的级别名称。
width = NULL,
#width:单个热图的宽度应该是固定的单位对象。 当热图附加到热图列表时,它用于布局。
show_heatmap_legend = TRUE,
#show_heatmap_legend:是否展示图例
heatmap_legend_param = list(title = name),
#heatmap_legend_param:热图图例设置(标题,位置,方向,高度等)参数列表,详情可见color_mapping_legend,ColorMapping-method。例如:heatmap_legend_param = list(title= “legend”, title_position =”topcenter”,
legend_height=unit(8,”cm”),legend_direction=”vertical”)
use_raster = FALSE,
#use_raster:是否将热图图像体渲染为光栅图像。当矩阵很大时,它有助于减小文件大小。如果设置了cell_fun,则强制use_raster为FALSE
raster_device = c(“png”, “jpeg”, “tiff”, “CairoPNG”, “CairoJPEG”, “CairoTIFF”),
#raster_device:用于生成光栅图像的图形设备
raster_quality = 2,
#raster_quality:设置为大于1的值将改善光栅图像的质量。
raster_device_param = list()
#raster_device_param:所选图形设备的其他参数列表。
)
实操篇
1)首先构建测试数据集
mat = rbind(mat, matrix(rnorm(40, -2), 4, 10)) #产生一个4行10列共40个平均值是-2的矩阵并与8行10列的矩阵合并成一个12行10列的矩阵
rownames(mat) = letters[1:12] #行名为a-l
colnames(mat) = letters[1:10] #列名为a-j
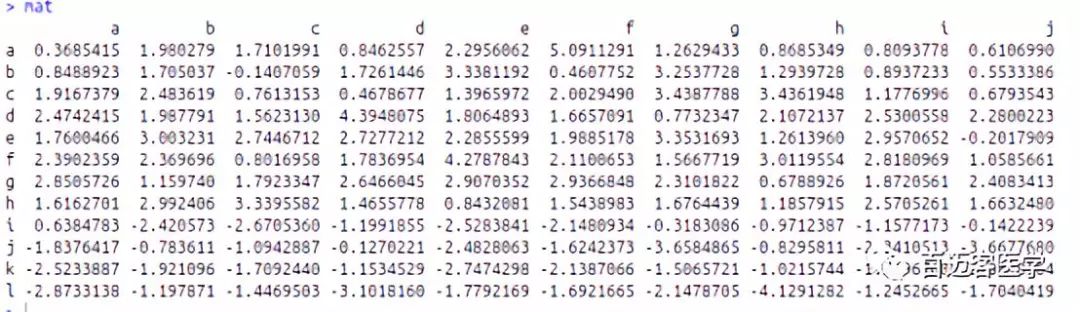
require(circlize) #加载circlize包,准备为热图设定需要的颜色参数
2)简单热图
我们总是对图形带给我们的直观感受赞不绝口。那么我们就先来看看单个热图的设计图形是什么样子的吧。
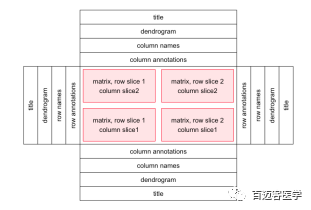
单个热图由热图主体和热图组件组成。 热图主体可以按行和列分割。 热图组件是标题,树形图,矩阵名称和热图注释,它们放在heamap体的四个侧面上。
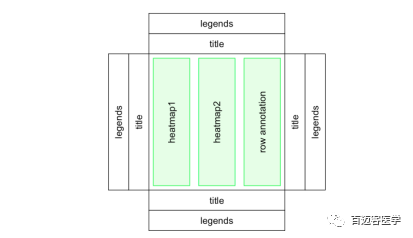
热图列表是热图和热图注释列表的串联,围绕热图列表,有全局的标题和图例。热图列表的一个重要内容是所有热图和注释的行(如果热图列表是水平的,则是行注释)都被调整,以便所有热图和注释中的相同行对应于相同的特征。行注释的热图列表:
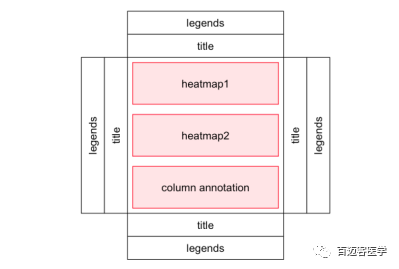
如果是列注释的话,热图列表则是:
name = “single heatmap”,
column_title = “good column”,column_title_side = “top”,column_title_gp = gpar(fontsize = 20, fontface = “bold”,col=”red”),column_title_rot = 0,cluster_columns = T,clustering_distance_columns =”euclidean”,clustering_method_columns = “complete”,column_dend_side =”top”,column_dend_height = unit(10, “mm”),show_column_dend =TRUE,column_dend_gp = gpar(),row_title = “luck row”)
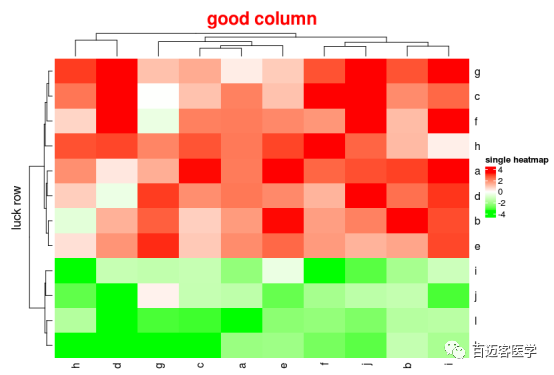 由此,我们可以很方便地更改图上的热图主体和热图组件的属性。
由此,我们可以很方便地更改图上的热图主体和热图组件的属性。#使用调色板
color <-colorRamp2(c(-2, 0, 2), brewer.pal(n=3, name=”RdBu”))
#随机取色
color<-structure(circlize::rand_color(6), names = c(1:6))
#渐变色
color <- colorRampPalette(c(“blue”, “red”))(6)
color <- rainbow(6) #彩虹色
#还可以用如下方式设置颜色
color <- heat.colors(6)
color <- terrain.colors(6)
color <- topo.colors(6)
color <- cm.colors(6)
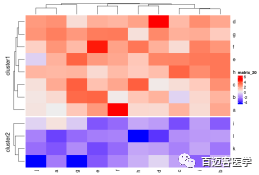 Heatmap(mat, split = rep(c(“A”, “B”), 6))
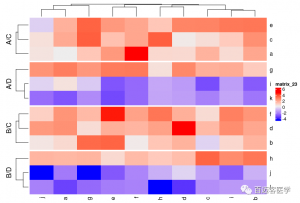
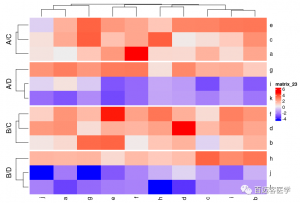
Heatmap(mat, split = rep(c(“A”, “B”), 6))Heatmap(mat, split = data.frame(rep(c(“A”, “B”), 6), rep(c(“C”, “D”), each = 6)))
Heatmap(mat, split = data.frame(rep(c(“A”, “B”), 6), rep(c(“C”, “D”), each = 6)), combined_name_fun = function(x) paste(x, collapse = “\n”))
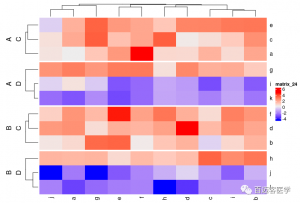 4)热图的简单注释
4)热图的简单注释
利用HeatmapAnnotation()对行或列注释。HeatmapAnnotation()函数会生成一个注释用的list。改函数的主要格式是HeatmapAnnotation(df, name, col, show_legend)。
value = 1:10
ha = HeatmapAnnotation(df = annotation, points = anno_points(value),
annotation_height = c(1, 2))
Heatmap(mat, top_annotation = ha, top_annotation_height = unit(2, “cm”),
bottom_annotation = ha)
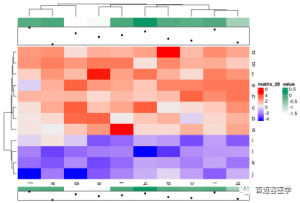 5)热图助力可视化肿瘤外显子高频突变基因的突变类型分布展示
5)热图助力可视化肿瘤外显子高频突变基因的突变类型分布展示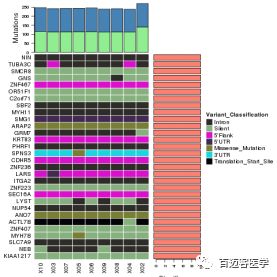

如果有任何问题,欢迎点击上方按钮咨询我们。




 京公网安备 11011302003368号
京公网安备 11011302003368号